The Science Behind screengrasp
Leading the Next Generation of AI-Powered Computer Control
The Evolution of AI Interaction
As Large Language Models (LLMs) continue to advance at an unprecedented pace, we're approaching a pivotal shift in human-AI interaction. The transition from chat-based interfaces to AI agents capable of executing complex tasks autonomously is not just inevitable—it's imminent.
This realization has sparked intense research and development efforts from industry leaders, innovative startups, and prestigious research laboratories. Notable breakthroughs have emerged from Allen AI with Molmo, Microsoft with OmniParser, and Anthropic with Computer Use.
The Challenge
While each approach brings unique strengths, no single solution has fully addressed the complexities of AI-powered computer control. Moreover, developers face significant hurdles in implementing these models, with each requiring specialized knowledge and complex setup procedures.
This is where screengrasp comes in—we've built a comprehensive solution that not only outperforms existing approaches but also simplifies their implementation.
Benchmark Results
Our extensive testing demonstrates screengrasp's superior performance across various scenarios and use cases:
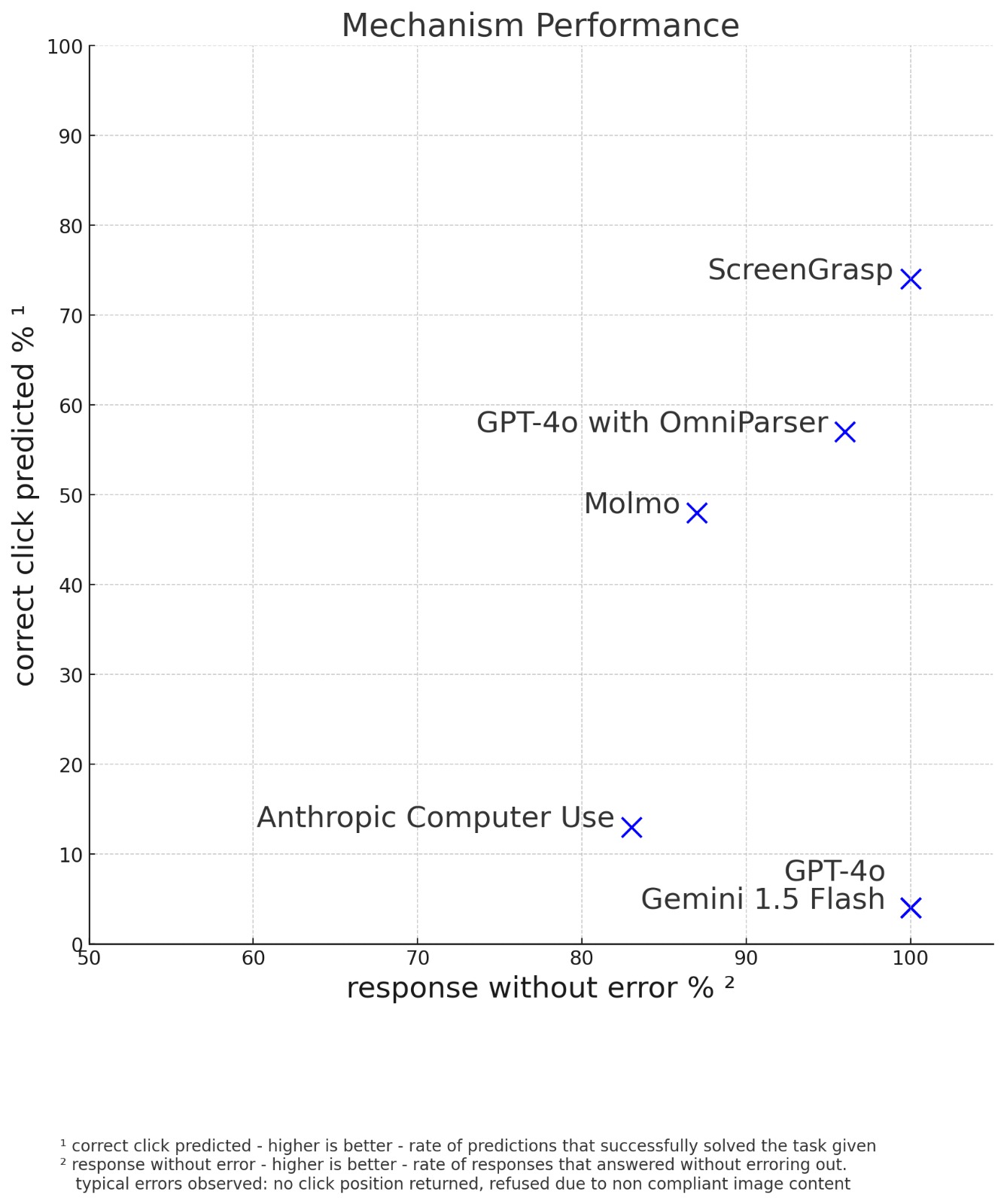
Key Advantages Over Existing Solutions
Our comprehensive analysis reveals several critical advantages of screengrasp over current alternatives:
- Superior Resolution Handling: While competitors struggle with standard desktop resolutions, screengrasp excels at processing high-resolution screenshots. For instance, Anthropic Computer Use cannot process images larger than WXGA (1366 × 768), and both Molmo and OmniParser face similar limitations with larger images.
- Balanced Compliance Approach: Unlike Anthropic Computer Use's overly restrictive compliance rules that can block legitimate click-point analyses, screengrasp implements smart, context-aware moderation that maintains security without hampering functionality.
- Multi-Language Excellence: Where Molmo struggles with non-English interfaces, screengrasp accurately identifies and interacts with UI elements across multiple languages and locales.
- Comprehensive Context Understanding: Unlike OmniParser's limited contextual awareness, screengrasp maintains full understanding of the entire screen context, ensuring more accurate and relevant interactions.
- Universal Compatibility: screengrasp excels at recognizing rarely-used icons and applications across various operating systems, addressing OmniParser's limitations with non-Windows environments.
These advantages are achieved through our unique ensemble approach, combining the strengths of leading models with proprietary enhancements and specialized techniques.
How does it work?
Screen Grasp 2 represents a breakthrough as the world's first Reasoning Click Prediction Model. Unlike traditional models that process all tasks with the same fixed approach, Screen Grasp 2 dynamically adapts its reasoning depth based on task complexity. For simple, straightforward tasks like "click the login button," it provides near-instant responses. For more challenging tasks like "find the setting to enable dark mode for code editors only," it engages in deeper reasoning, methodically analyzing the interface.
This adaptive reasoning is powered by our innovative sequential verification approach. The model intelligently tries predictions from multiple leading models (LLABS, Qwen, Gemini, Anthropic, and Molmo) in sequence, verifying each prediction before proceeding. This ensures we get the most accurate result while optimizing computational resources based on task difficulty.
Each prediction is verified using advanced visual understanding techniques to confirm whether the predicted click position truly matches the user's intent. This verification step is crucial in eliminating false positives and ensuring reliable results across diverse UI scenarios.
We will continue to improve Screen Grasp 2's reasoning capabilities by integrating new models and refining our verification process to maintain our position at the forefront of UI interaction prediction.
A Unified Solution
screengrasp.com offers not just exclusive access to our leading model, but also provides a streamlined interface for utilizing other powerful solutions like Anthropic Computer Use, Molmo, and OmniParser—all with minimal learning curve.
About Our Benchmarks
While we maintain full transparency in our methodology, we currently cannot make our complete benchmark suite public due to privacy considerations in our test data. Additionally, we're in the process of preparing our benchmark code for public release.
We welcome independent verification of our results and encourage interested parties to conduct their own benchmarks.